Илья Мунерман, Исследовательский центр Интерфакс-ЛАБ, директор
Самая распространенная проблема скоринга сейчас состоит в том, что не все могут быстро интерпретировать результаты, которые выдала модель, так как сложный алгоритм исследует десятки факторов в динамике, и не все их сразу же видят и понимают, о чем речь. В статье описан алгоритм, который автоматически естественным языком объясняет, какие слабые или сильные стороны бизнеса повлияли на принятие решений. Зачем это банку? Для повышения скорости и культуры корпоративной коммуникации и эффективного диалога с клиентом.
Скоринговые системы в глазах обычных людей выглядят черным ящиком, что явно снижает к ним доверие. Классический вопрос из службы поддержки: «Что не так с этой компанией?» Многие клиенты возмущаются по поводу неадекватных кредитных предложений и лимитов, которые в них устанавливаются. Тем не менее, как только мы раскрываем факторное пространство, которое используется для построения скоринга, мошенники немедленно получают инструмент манипулирования наиболее значимыми показателями скоринговой модели.
Все это говорит о том, что нужно научить скоринговые модели «разговаривать» с клиентом. Как при этом соблюсти требования безопасности, обсудим несколько позже.
NLP Pipeline
На рисунке представлена схема, получившая название NLP Pipeline (NLP в данном случае — это natural language processing, а не нейролингвистическое программирование, как некоторые думают). Любой чат-бот, любой генератор естественного языка, будь то Siri, Alexa или Алиса, работает именно по этой схеме, ставшей общеупотребительной.
На первом этапе происходят распознавание речи и перевод звуков в символы, слова, предложения. Для письменной речи данный этап отсутствует. Из математических моделей на данном этапе чаще всего используется глубокое обучение на нейронных сетях.
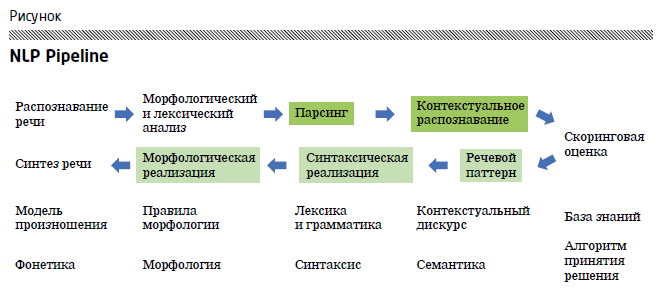
Далее текстовый документ преобразуется в более удобную машиночитаемую форму с помощью процедур стемминга и лемматизации. Нужно сказать, что данный этап представляет из себя кошмар любого филолога, так как на этой стадии уничтожаются падежи (все, что остается, — это активный или пассивный залог), обрезаются делающие речь красивой, но не несущие смысловой нагрузки суффиксы и окончания. В результате текст максимально приближается к машиночитаемой форме.
Многие считают, что данный этап сильно зависит от сложности грамматической структуры языка, однако это верно лишь отчасти, так как современные процессоры в состоянии обрабатывать даже очень сложные языки и извлекать факты из написанных на них текстов, несмотря на их грамматическую сложность. Так что анализ текста на венгерском или исландском будет лишь на несколько миллисекунд длиннее аналогичного анализа текста на английском. А вот отсутствие библиотек для анализа текстов на сложных языках — это действительно серьезное препятствие.
Следующий этап — превращение текста в таблицы при помощи связанных с этим алгоритмов, реализующих теорию формальных грамматик, таких как «мешок слов», word to vec и др. На этом этапе текст переводится в базу данных и от него остаются только смысловые конструкции, а не его полная грамматическая структура. Осуществляется онтологический разбор текста, превращающий его в набор формальных конструкций, таких как объекты и субъекты, свойства и методы, эти свойства изменяющие.
Наконец, определяются контекст и связанные с контекстом смыслы фактов, которые в тексте изложены: это интересный этап, который в наибольшей степени зависит от контекстнозависимости языка и конкретного текста. Так, юридические и другие формальные виды текстов гораздо проще анализировать, чем художественные произведения. В итоге на данном этапе текст окончательно превращается в таблицу, которая отправляется на вход скоринговой модели[1].
Далее нет смысла лишний раз рассказывать, как скоринговая модель обрабатывает поступившие на вход данные, как она тестируется, обучается и переучивается. Но как только скоринговые оценки получены и на их основе принято решение, начинается самое интересное: все элементы, про которые мы писали выше, начинают повторяться в обратном порядке.
На основе контекста выбирается подходящий словарь, составляется предложение правильной грамматической структуры, расставляются падежи, рода и склонения и, наконец, если в этом есть нужда, синтезируется естественная речь, которая интерпретирует результат, полученный методами машинного обучения.
Таким образом, мы описали алгоритм, который автоматически естественным языком объясняет, какие слабые или сильные стороны бизнеса или человека повлияли на принятие в отношении его тех или иных решений. Гораздо лучше не просто получить отказ, а узнать основные причины, которые повлияли на принятие решения. Более того, при этом может обнаружиться ошибка в клиентских данных, которую удастся оперативно устранить, что приведет к повышению лояльности клиента и росту продаж. Также использование этой технологии позволяет не отвлекать сотрудников на попытки объяснить словами, как работает скоринговая модель и почему она работает правильно.
Пример практической реализации
В системе СПАРК рассчитывается индекс финансового риска, о котором мы много писали ранее[2]. Именно с него мы приняли решение начать формирование алгоритма лингвистического вывода, объясняющего значение полученной скоринговой оценки для компаний, у которых есть финансовая отчетность.
Построенный алгоритм обучался на основе лучших текстов финансового анализа, написанных вручную, и составил набор фраз, которые обычно используются для описания успехов или проблем компании. Все полученные фразы были распределены по совместимости друг с другом; также был разработан счетчик, который не позволяет формировать дважды одно и то же предложение. Для объяснения значений индекса используются базисы объяснения, традиционные для классического финансового анализа. Рассмотрим некоторые из них:
- Среднеотраслевой и среднерегиональный уровни. В некоторых странах, например в Германии, предпочитают использовать нормированный на одного сотрудника показатель. Очевидно, что отдельные показатели финансового анализа, демонстрирующие существенное отклонение от среднего уровня, могут нести как положительную, так и отрицательную смысловую нагрузку. Например, большая рентабельность положительная, а долговая нагрузка отрицательная.
- Предыдущие периоды. Многие исследования показывают, что нет очевидной связи между текущим и предыдущим периодами и положение может измениться стремительно. Тем не менее, отметить изменение какого-то показателя во времени также представляется целесообразным.
- Контрольные значения из объективных источников. К таким источникам относятся научные статьи и нормативные акты. Ни для кого не секрет, что если у компании заниженный уровень показателей, соответствующих критериям ФНС для проведения в отношении налогоплательщика контрольных мероприятий, то риск, связанный с этой компанией, достаточно велик.
Как же избежать проблем, о которых шла речь выше, а именно: устранить риск раскрытия факторного пространства и сложности объяснения зависимостей между факторами?
Здесь нам на помощь приходит то обстоятельство, что современные скоринги отличаются высокой мобильностью. Технологии обучения в режиме реального времени легко позволяют изменить роль тех факторов, которые оказывают влияние на принятие итогового решения. Это делает бессмысленными попытки мошенников «хакнуть» систему: пока они будут создавать компанию или заемщика, соответствующих критериям, о значимости которых они узнали, изменятся внешняя среда и описывающие ее скоринговые модели и все усилия будут напрасны.
Сложнее объяснить, что роль фактора меняется в зависимости от того, в окружении каких других факторов он оказался, как и объяснить нелинейные зависимости. Пока текстовый документ может только сказать о наличии таких взаимосвязей, но не интерпретировать их естественным языком, но технологии постоянно совершенствуются и, возможно, технологии объяснения таких зависимостей скоро появятся.
Далее рассмотрим два примера финансового анализа, выполненного с помощью описанного нами алгоритма[3].
АО «АРЗ-5»
Чистая норма прибыли (ROS) характеризовалась ростом на 29,38%. Рентабельность продаж упала на 81,33%.
Совокупный долг снизился на 24,89%. Собственный капитал показывает сокращение на 161,87%.
Сокращение периода погашения дебиторской задолженности составило 51,33%.
Отметим уменьшение оборотных активов на 63,4%. Долгосрочные обязательства снизились на 43,6%. Коэффициент текущей ликвидности демонстрирует падение на 59,22%. Коэффициент абсолютной ликвидности упал на 73,5%. Коэффициент быстрой ликвидности сократился на 66,62%.
Валовая рентабельность выше среднеотраслевого показателя на 25,13%. Коэффициент текущей ликвидности ниже среднеотраслевого значения на 35,55%.
Валовая рентабельность выше среднего значения по региону на 26%. Рентабельность продаж ниже среднерегионального значения на 42%.
В целом, несмотря на некоторые негативные сигналы, можно сделать вывод о позитивном финансовом состоянии компании АО «АРЗ-5».
ООО «Равновесие»
Выручка возросла на 36,47%. Чистая норма прибыли (ROS) показывает прирост на 114,1%. Валовая рентабельность увеличилась на 111,19%.
Собственный оборотный капитал вырос на 103,84%.
Период погашения кредиторской задолженности снизился на 42,97%.
Отметим рост оборотных активов на 32,04%. Коэффициент текущей ликвидности вырос на 35,4%.
Валовая рентабельность ниже среднего значения по отрасли на 26,52%. Коэффициент текущей ликвидности ниже среднеотраслевого показателя на 79,58%. Коэффициент быстрой ликвидности ниже среднего уровня по отрасли на 63,52%.
Рентабельность продаж ниже среднерегионального показателя на 40%.
В целом, несмотря на некоторые позитивные сигналы, можно сделать вывод о негативном финансовом состоянии компании ООО «Равновесие».
Примечания
- Мунерман И., Федотов Н. Как вычислить исковую нагрузку российских компаний: модели Legal Tech // Внутренний контроль в кредитной организации. 2019. № 3.
- Воронцов И., Мунерман И. Как прогнозировать неплатежеспособность заемщика в условиях недостаточных или недостоверных данных? // Банковское кредитование. 2019. № 2.
- Автор выражает признательность аналитику Объединенного кредитного бюро Никите Федотову за подготовку примеров.
Источник: журнал "Внутренний контроль в кредитной организации"
Читайте также:
Данные онлайн-касс как инструмент мониторинга контрагентов
СПАРК научился прогнозировать размер исковой нагрузки компаний